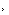|
天然劣势以及多年来的数据和手艺堆集凭仗着搜狗互联网公司文字消息获取的,结构天然言语处置范畴搜狗从2012年起头,狗知音天然言语处置平台并于2016年推出搜。于供给模块化的产物办事以及处理方案搜狗知音天然言语处置平台次要聚焦。前目,、语音阐发、机械翻译等通用模块该平台以囊括语音识别、语音合成,户进行自在组合以便让平台用,营业场景的客制化处理方案从而建立合适其行业以及。几年近,户的反馈通过客,、企业办事、科研教育等范畴的专有处理方案搜狗知音天然言语平台已构成针对体裁文娱,搜狗兼顾并推出了,处理方案以加速平台用户落地脚步搜狗同传等泛化行业垂直范畴性。前目,育、金融等范畴都有离散使用落地搜狗兼顾与搜狗同传在传媒、教。
站、微信、微博、APP等接入体例智齿客服产物支撑桌面网站、挪动网,将多平台顾客汇集于统一平台办理用户只需把代码复制到网站上即可,简洁操作。
元、各类寄放器以及存储单位DSP内有节制单位、运算单,储器和必然数量的外部设备其外围还能够毗连若干存,的全面功能有软、硬件,微型计较机本身是一个,速度快、体积小运算能力强、,具有高度的矫捷性并且采用软件编程。能并未通过实践验证但目前DSP的性,PU相匹敌的芯片器件也未出产出能够与G,在研发过程中贸易化使用仍。

阶段现,天然言语处置运算的芯片行业内尚未呈现特地用于,施行天然言语处置布局化运算焦点数据处置芯片CPU无法,GPU、FPGA、ASIC和DSP目前合用于天然言语处置的芯片类型有。
中需要现实学问并将其存储在模子参数中PLM的靠得住学问编纂:PLM在锻炼,各类使命等以用于下流,识具有时效性但大量现实知,在不精确或过时的问题跟着时间推移可能会存。高效方式来批改模子中对应学问开辟靠得住的、无需从头锻炼的,的PLM的环节问题是实现高质量靠得住。
市场由根本资本供应商构成天然言语处置财产链上游,、云办事、数据库等软、硬件供应商涉及收集设备、办事器、芯片、存储,品开辟商供给需要的资本支撑担任为天然言语处置手艺和产。
曾经在多项使命上取得了超越人类的表示PLM的持续学问加强:虽然PLM模子,用智能程度增加仍碰到瓶颈可是此刻PLM的模子通。见的将来在能够预,机能将持续增加PLM模子的。数据提拔模子言语处置能力若何持续进修新学问、新,植入的PLM进修机制成立高效的学问持续,环节研究标的目的是PLM的。
的营业处置智能化程度要求上涨金融、医疗、法令等保守行业,外行业使用中的落地历程加快天然言语处置手艺。如例,金融范畴的智能投研、智能投顾、智能客服和智能运营等场景实现使用智能问答、资讯舆情阐发、文档消息抽取、文档主动生成等使用逐步在。研场景中在智能投,量金融资讯消息以控制金融市场动态投研人员每天需要通过多渠道搜刮大,标的公司严重旧事、通知布告、财政情况而金融资讯消息极为丰硕(如涉及,政策律例变化、社交媒体评论等)金融产物消息、宏观经济情况、,量复杂数据,讯库中搜刮并阅读阐发相关内容单靠投研人员从浩如烟海的资,花费严峻时间精神,难以提高工作效率,环境下在此种,文摘(阐发文章的次要内容)及资讯个性化保举功能的资讯舆情阐发使用逐渐遭到投研人士和金融机构的推崇具备资讯分类(按公司、产物、行业范畴分类)、感情阐发(阐发旧事、公司或产物的正负面消息)、主动,据主动摘要、归纳、缩简和抽取资讯舆情阐发使用对海量定性数,高效的消息展现为投研人员供给,索以及摘取资讯的时间大幅缩短投研人员搜,工作效率提高其。
q)是一种通用且功能强大的范式序列到序列范式(Seq2Se,种NLP使命能够处置各。由编码器—解码器框架实现Seq2Seq范式凡是,�1如�,⋯,(ENC(𝑥1𝑦𝑚=DEC,⋯,�))𝑥�。Lab分歧与Seq ,的长度不需要不异这里输入和输出。
问答等使用中有主要感化语法阐发在机械翻译和。方式是两种常用的手段基于转移和基于图的。q2ASeq范式前者凡是利用Se,ass范式处理尔后者利用Cl。线性化为一个序列通过将方针树布局,q2Seq范式处理该使命能够通过Se。外此,RC范式来处理依存阐发使命Gan et al.利用M。
关的研究工作连系国表里相,学问的NLP的手艺趋向下面归纳综合性地总结基于。方面一,够主动进修语义的分布式暗示面向NLP的深度进修手艺能,能力强表达,使命中获得充实验证已在NLP多项主要,的方式研究奠基了坚实根本为进一步融入学问指点消息。方面另一,初步具备完整的方式系统学问暗示与推理手艺曾经,识付与了人工智能分歧的能力充实操纵人类各类型布局化知,性和鲁棒性供给了支持为提拔模子的可扩展。
针对的是纯文本数据目前消息抽取次要,的结构且包含丰硕的消息而常见的文档具有多样,现包含大量的多模态消息以富文本文档的形式呈,的角度来说从认知科学,越多种感官消息的融合处置人脑的感知和认知过程是跨,感情、能够通过视觉消息补全文本中的缺失消息等如人能够同时操纵视觉和听觉消息理解措辞人的,也该当是针对多模态的富文档消息抽取手艺的进一步成长。述阐发基于上,一是多模态消息的融合消息抽取的成长标的目的之。态预锻炼模子的设想具体包罗:1)多模;架中跨模态对齐使命设想2)多模态消息抽取框;息的提取和暗示3)多模态信。
Matching范式中进行建模天然言语推理(NLI)凡是在,本(𝒳𝑎两个输入文,编码并互相感化𝒳𝑏)被,预测它们的关系再毗连分类器。能强大的编码器呈现跟着BERT等功,为一个文本在Class范式中处理NLI使命能够通过将两个文本毗连。
就是一种天然的标注数据其实文本本身的挨次性,(又称言语模子)就能够形成一项源使命通过若干持续呈现的词语预测下一个词语。本数据规模近乎无限因为图书、网页等文,得超大规模的预锻炼数据如许就能够很是容易地获。督进修(Unsupervised Learning)有人将这种不需要人工标注数据的预锻炼进修方式称为无监,并不精确其实这,的(Supervised)由于进修的过程仍然是有监视,supervised Learning)更精确的叫法该当是自监视进修(Self。
数据驱动的体例获得各类语义关系的统计模式现有的神经收集消息抽取方式依托深度进修以,原始数据中进修相关特征其劣势在于能从大量的,用证据和现实比力容易利,样融合专家学问可是忽略了怎。络进行消息抽取纯真依托神经网,确率之后到必然准,再改良就很难。学问获取来看从人类进行,利用先验学问以及证据良多决策的时候同时要。拟人脑进行消息抽取的环节挑战数据驱动和学问驱动连系是模。述阐发基于上,数据驱动和学问驱动融合抽取手艺消息抽取的成长标的目的之一是建立。进修消息抽取框架的建立具体包罗:1)神经符号;逻辑符号的对应关系2)进修神经收集到;号计较过程进行模仿3)神经收集对于符。
据并行计较问题劣势较着GPU处理浮点运算、数,度运算能力可供给高密,元素并行问题处理大量数据。芯片功耗大但GPU,构办事器而运转依托于X86架,昂扬成本,言处置产物方案的开辟不合用于普遍的天然语,数字化历程连系加深的趋向下在天然言语处置与保守行业,运算芯片的方案不具备成本劣势采用GPU作为天然言语处置,项目承担不起昂扬成本小型天然言语处置使用。
用的范式归为以下7类NLP使命中普遍使,)、序列到序列(Seq2Seq)、序列到动作序列(Seq2ASeq)和言语模子((M)LM)即分类(Class)、婚配(Matching)、序列标注(Seq Lab)、阅读理解(MRC。
研究兴旺成长消息抽取手艺,人工智能等范畴的主要分支曾经成为了天然言语处置和。际权势巨子评测和会议的鞭策这一方面得益于系各国,列会议(MUC如动静理解系,nding Conference)Message Understa,评测(ACE主动内容抽取,action)和文本阐发会议系列评测(TACAutomatic Content Extr,s Conference)Text Analysi。取手艺的主要性和适用性另一方面也是由于消息抽,界和工业界的普遍关心使其同时获得了研究。度推进了中文消息处置研究的成长消息抽取手艺本身的成长也大幅,向现实使用需求迫使研究人员面,现的研究难点和重点起头注重之前未被发。
力强、规模量产成本低ASIC芯片的运算能,者完成所有电路的设想全定制设想需要设想,周期长开辟,本昂扬时间成,要求较高、开辟周期较长的范畴次要合用于量大、对运算能力。
函数怀抱,实的合理性用于权衡事。:1)基于距离的怀抱函数目前有两种典型的怀抱函数,离来权衡现实的合理性通过计较实体之间的距,关系的上平移被普遍利用此中𝒉+𝒓≈𝒕,rans H、Trans R等代表方式有Trans E、T。似性的怀抱函数2)基于语义相,权衡现实的合理性通过语义婚配来。𝒉⊤𝑀𝑟≈𝒕它凡是采用乘法公式,t Mult、ComplEx等代表方式有RESCAL、Dis。
P使命规范为同一框架的潜在能力一些范式曾经显示出将各类NL,P使命的同一处理方案的可能性供给了将单个模子作为分歧NL。要大量标注数据、泛化能力强以及摆设便利单个同一模子的劣势能够归纳综合为:不再需。
言单元(包罗词汇、句子和篇章等)进行主动语义阐发语义阐发通过成立无效的模子使计较机系统能对各个语,言文本的实在语义从而理解天然语。的言语单元分歧按照理解对象,句子级语义阐发以及篇章级语义阐发可将语义阐发分为词汇级语义阐发、。何获取或区别单词的语义词汇级语义阐发关心如,整个句子所表达的语义句子级语义阐发关心,章文本内言语单位(句子、从句或段落)间的语义关系篇章级语义阐发研究篇章文本的内在布局以及理解篇。
向量预锻炼模子晚期的静态词,词向量预锻炼模子以及后来的动态,18年以来出格20,模子刚好填补了天然言语处置标注数据不足的错误谬误以BERT、GPT为代表的超大规模预锻炼言语,取得了一系列的冲破协助天然言语处置,然言语处置使命机能都获得了大幅提高使得包罗阅读理解在内的几乎所有自,达到或跨越了人类程度在有些数据集上以至。
世界没有太多交互目前的大模子与。情境需要与世界进行交互而语义阐发使命中有些,话施行查询如基于对,行指令操作等基于对话执。解的能与世界进行交互的大模子若何锻炼一个面向天然言语理,当前的动作发生改变时即当世界的形态由于,感知到形态的变化大模子可否及时的,是基于已更新过的世界形态的并在理解下个输入的过程中,可探究的点也是一个。
2014年5月智齿科技成立于,办事的互联网创业企业是一家供给智能客服。进修及大数据手艺进行无效整合智齿科技将天然言语理解、机械,智能外呼机械人在内的智能全客服平台和智能外呼平台建立了包罗云呼叫核心、智能机械人客服、人工在线、,样化的智能客服办事为企业用户供给多,下保守客服所不克不及处理的企业客服痛点为用户处理挪动时代、体验经济情况。4月获得由云启本钱领投智齿科技于2018年,机构跟投的1.5亿元人民币B+轮融资耀途本钱、上海原龙投资和博雅盛景等。
:常规NER、嵌套NER和非持续NER定名实体识别(NER)能够被分为3类。s和Seq2ASeq来别离处理3个使命保守的方式基于Seq Lab、Clas。ER和嵌套NER规范为MRC使命Li et al.提出将常规N。Seq范式的同一模子来处理所有3种子使命Yan et al.利用一种基于Seq2。
P深度进修模子的融合完成学问图谱到NL,的预锻炼言语模子等环节手艺涉及学问暗示进修、融合学问。
场景具有庞大鸿沟抱负设定与现实,对现实使用中的挑战展开近期越来越多的工作针。、事务具有长尾分布特点实在场景中实体、关系,体对的示例较少很多关系和实。疗等垂直范畴对于金融、医,现象更为较着缺失标注数据,获取也很坚苦以至数据的,的“数据饥渴”模子而神经收集作为典型,机能会遭到极大影响在锻炼样例过少时。样本使命针对小,6种细粒度实体类的少样本定名实体识别Ding等发布了包含8种粗粒度和6;抽取数据集Few RelHan等发布了小样本关系,的根本上提出了FewRel2.0Gao等在Few Rel数据集,是”检测(noneof-the-above detection)添加了范畴迁徙(domain adaptation)和“以上都不。的语义特征是少量样本快速进修学问的代表性方式操纵海量无监视数据获得的预锻炼模子获得无效,RT来对文本关系进行暗示Baldini等利用BE,锻炼使命不成知(task agnostic)的关系抽取模子而且提出了Matching the blanks的方式来预。
型等问题对天然言语处置进行了浩繁范畴自顺应的调试虽然近年来研究者们针对言语模子、语序模子、腔调模,决片面的自顺应问题但每种调试方式只能解,仍然无法处理通用性问题。处理天然言语处置方面的所有问题天然言语处置厂商无法用单一模子,分歧范畴只能按照,天然言语模子开辟响应的,域的学问库运转相关领,的天然言语问题处置特定范畴。使用尚未普及但在目前行业,不清晰的环境下产物贸易模式并,数使用以及各类范畴开辟公用算法天然言语处置厂商缺乏动力为少,术难以大范畴推广落地导致天然言语处置技。
词性标注这一使命词法阐发次要包罗。为输入文本中的每个词进行词性标注的过程词性标注指基于词性寄义以及词的上下文来,词、动词、描述词等常见的词性标签出名。有间接使用场景词性标注一般没,下流使命供给协助但它却能为很多,如例,歧使命傍边在词义消,常是相联系关系的词义和词性常,可指职业也可指行为好比“翻译”一词既,性分歧:前者为名词尔后者为动词这两个词义的一大区别即为其词。
术成长敏捷语义阐发技,体上整,理范畴的成长大潮紧跟天然言语处,于其他使命的先辈手艺一方面部门方式开导,列的语义阐发方式如基于序列到序,也开导了其他范畴另一方面部门方式,的事务抽取方式如基于受限解码。
量数据的场景能率先推出杀手级使用环节成功要素:在使用较普遍且有海,累用户从而积,行业的主导者成为该垂直;海量数据通过堆集,用手艺、根本算法拓展逐渐向使用平台、通。
能的深切成长跟着人工智,需求不竭提拔天然言语处置,言处置手艺协助其实现智能化浩繁类型智能使用需要天然语,类、看法挖掘、舆情阐发、主动判卷系统、消息过滤和垃圾邮件处置等使用如(1)文本范畴的搜刮引擎、消息检索、机械翻译、主动摘要、文天职;说和智能近程讲授与答疑等使用均需天然言语处置手艺理解或生成天然言语(2)语音范畴的语音助手、智能客服、聊天机械人、主动问答、智能解。
算法研究笼盖面广百度天然言语处置,、语义计较、言语阐发、学问挖掘等天然言语处置细分范畴涉及深度问答、阅读理解、智能写作、对话系统、机械翻译。阐发与聚合等环节的一整套深度问答手艺方案百度堆集领会决问句理解、谜底抽取、概念,览器、百度翻译、百度语音助手、小度机械人等多个产物中目前已将该套手艺方案使用于百度搜刮引擎、百度手机浏。言篇章理解方面百度在天然语,内容标签、感情阐发等环节手艺构成篇章布局阐发、主体阐发、,度消息流、糯米等产物中实现使用且该类环节手艺已在百度搜刮、百。手艺研究次要为旗下产物办事阿里巴巴开展天然言语处置,建立学问图谱实现智能导购如阿里巴巴在其电商平台中,趣挖掘实现精准营销对电商用户进行兴,场景中实现机械人供给客服办事在蚂蚁金融、淘宝卖家等客服,品消息翻译、告白词翻译以及买家采购需求翻译等在跨境电商营业中采用机械翻译办事进行商家商。
理算法供给商、处理方案供给商以及使用产物开辟商天然言语处置财产链中游市场主体次要有天然言语处。算法、处理方案以及使用产物功能于一身目前中国的天然言语处置厂商较多集研发,然言语处置算法厂商自主研发自,言处置环节手艺方案构成一整套天然语,及手艺方案内嵌于自有使用产物系统中并将自主研发的天然言语处置算法以,、阿里巴巴和腾讯典型代表有百度。
天然言语处置的根本使命词法阐发和句法阐发是,言语处置下流使命中去能够被使用到很多天然,译和文本摘要例如机械翻。
9年2月201,管理专业委员会成立国度新一代人工智能,理准绳——成长负义务的人工智能》并于6月发布了《新一代人工智能治,成长与管理的关系旨在“更好地协调,平安靠得住可控确保人工智能,生态可持续成长”鞭策经济、社会及。4月同年,了《人工智能伦理风险阐发演讲》国度人工智能尺度化总体组发布,准绳”和“义务准绳”提出“人类底子好处。9年5月201,智能研究院成立了人工智能伦理与平安研究核心由科技部和北京市当局指点成立的北京智源人工,度、阿里、腾讯、华为等)和其他学术机构及财产组织配合发布《人工智能北京共识》并结合北大、清华、中科院、新一代人工智能财产手艺立异计谋联盟(倡议成员包罗百,于人类命运配合体的建立和社会成长”的15条准绳提出了人工智能研发、利用和管理应遵照的“无益。9年8月201,十家企业结合发布《新一代人工智能行业自律公约》深圳人工智能行业协会与旷视科技、科大讯飞等数。提出了企业本身的AI伦理原则百度、腾讯等次要科技企业也;定原则的根本上旷视科技还在制,能道德委员会成立了人工智,、有价值的人工智能生态”以鞭策“可持续、负义务。
个夹杂神经收集翻译引擎①定制化机械翻译是一,办理企业语料该办事能同一,数据和办理账号给企业特定的,细化、专业性的需求满足企业个性化、精,隐私和数据的结果达到庇护企业数据。
市场主体为根本资本供给商天然言语处置财产链上游,商等)和软件供应商(如云办事供应商和数据库供应商等)包罗硬件供应商(如芯片供应商、办事器供应商和存储供应;理处理方案供应商以及天然言语处置使用供应商构成中游市场由天然言语处置算法供应商、天然言语处,求端供给办事担任为下流需;为各类型用户下流市场主体,户和小我用户包罗企业用,、出行办事、互联网办事等范畴企业用户涉及金融、医疗、教育,为最终消费者小我用户则。
营业行业办事经验丰硕智齿科技的智能客服。行业建立学问图谱智齿科技在26个,40个细分场景学问图谱此中16个行业建立了,行业客服机械人问答供给行业学问库及,内容笼盖面广问答语料库,供给智能客服问答办事能为浩繁范畴行业用户,的企业数量超5万家目前智齿科技办事过,办事、在线教育、互动文娱等多个细分行业笼盖电商、互联网金融、糊口办事、企业,、新东方、搜狐、发卖易等出名企业用户包罗用友、富士康、滴滴出行、趣分期。
于高质量的标注数据难以获取的问标题问题前的面向语义阐发的预锻炼模子由,eneration等数据相对容易获取的问题上得以实现预锻炼模子还只在text-to-sql和code g。下来接,加通用的语义阐发情境能够测验考试同时面向更,放域的问答如面向开,施行指令等言语到机械,锻炼模子一个预,语义阐发使命合用所有的。
耕算法和通用手艺环节成功要素:深,术劣势成立技,使用为入口同时以场景,用户堆集。
上综,呈现了一种较着的“同质化”趋向能够看出天然言语处置的成长汗青。写特定的逻辑将输入文本转换为更高级此外特征晚期的天然言语处置算法需要按照分歧的使命编,法(如支撑向量机)进行成果预测然后利用相对同质化的机械进修算;后此,化的模子架构(如卷积神经收集)深度进修手艺可以或许利用愈加同质,间接进行进修在输入文本上,”出用于预测的更高级此外特征并在进修的过程中主动“出现;化的特征愈加较着而预锻炼模子同质,练模子(如BERT、Ro BERTa、BART、T5等)目前几乎所有最新的天然言语处置模子都源自少数大规模预训。可以或许做到一次预锻炼GPT-3模子更是,练样本)完成特定的下流使命即可间接(或仅利用少少量训。
服、工单系统、外呼机械人等SaaS客服产物智齿科技推出云呼叫核心、客服机械人、在线客,、政企等范畴的客户供给一站式客服处理方案为金融、教育、电商、企服、糊口消费、互娱,富的统计阐发报表同时建立了多元丰,勾当成果验收、客服人工工作量及效率协助企业用户阐发顾客关心核心、营销,供给数据支持为客服主管,学运营决策辅助企业科。
言处置的焦点使命语义阐发是天然语,言输入的语义理解其方针是实现对语,的操作和处置进而支持后续。论上在理,、认知科学、神经科学等多个学科语义阐发涉及言语学、计较言语学,鞭策多个相关学科的成长语义阐发的研究和进展可。用上在应,的其他使命都有必然的推进感化语义阐发对天然言语处置范畴。机械翻译如现代,得媲佳丽类以至跨越人类的翻译结果虽然目前的神经机械翻译系统已取,、达、雅”的尺度但要真正达到“信,义阐发的参与还需要有语。义搜刮引擎如现代的语,为了理解用户提交的查询的企图从以前的婚配查询与文档改变,回最合适需求的搜刮成果可以或许更精准的向用户返。外另,取方面学问获,是彼此推进的它与语义阐发,方面一,要学问的支持语义阐发需,对语义阐发有着至关主要的感化更大、更全、更精确的学问库;方面另一,取更多布局化的学问为了从自在文本中获,必不成少的手艺语义阐发又是。
M)LM、Matching、MRC和Seq2Seq次要切磋以下4种可能同一分歧NLP使命的范式:(。是操纵预锻炼言语模子的天然体例将下流使命规范为(M)LM使命。数据处置理解和生成使命(M)LM可利用无监视。式是Matching另一个可能的同一范。在于只需要设想标签描述Matching的劣势,量较小工程。大量NLI数据进一步锻炼但Matching需要,移受限范畴迁,生成使命且无法做。定的问题并锻炼MRC模子MRC范式通过生成使命特,题选择准确的span从输入文本中按照问。模子十分通用MRC的框架,锻炼模子的能力但难以阐扬已有。个通用且矫捷的范式Seq2Seq是一,于复杂使命很是合用,成导致较慢的推理速度但也受限于自回归生。
化的智能家居处理方案思必驰具有软硬一体,个性叫醒、语音识别、语义理解、对话交互等功能为智能家居产物供给高机能、低成本的声源定位、,场、远场的语音交互使家居产物可顺应近,户节制便利用,的智能化程度提高家居产物。
2014年12月新译科技成立于,能手艺的科技公司是一家研发人工智,识别等手艺为根本以机械翻译和语音,网言语办事平台等一系列关于翻译范畴的产物和办事向用户供给在线机械翻译、在线辅助翻译平台和互联。件智能翻译为承载体新译科技以软、硬,路”多语传布平台扶植办事于国度“一带一,范畴供给全球化根本性多语沟通办事为金融、专利、法令、医学等垂直。
处置和人工智能的焦点手艺消息抽取手艺是中文消息,的科学意义具有主要。消息布局化和语义化通过将文本所表述的,非布局化文本的无效手段消息抽取手艺供给了阐发,识化和普适化的焦点手艺是实现大数据资本化、知。常以布局化的形式描述被抽取出来的消息通,机间接处置可认为计较,析、组织、办理、计较、查询和推理从而实现对海量非布局化数据的分,学问库建立、智能问答系统、舆情阐发系统)供给支持并进一步为更高层面的使用和使命(如天然言语理解、。
先对外发布讯飞开放平台2010年科大讯飞率,术及数据劣势操纵本身的技,相对完美的AI产物系统搭建讯飞开放平台并供给,及语义理解等AI手艺接入供给语音识别、语音合成以。托本身手艺劣势讯飞开放平台依,了丰硕的手艺模块产物与处理方案针对分歧业业以及办事场景都推出。音识别、语音合成、感情阐发、环节字提取等)平台不但有成熟的手艺产物模块化办事(包罗语,办理软件以及硬件等一揽子办事还可针对上述模块供给对应的。前目,建立笼盖该范畴上、中、下流的全套处理方案科大讯飞不只正在寻求通过天然言语处置平台,医疗、体裁文娱、及企业办事等保守范畴还但愿该全套处理方案能够顺应如健康,平台客户的粘着性从而进一步加强。
方式:抽取式摘要和生成式摘要处理文本摘要使命有两种分歧的。eq Lab范式前者凡是利用S,2Seq范式间接生成尔后者常通过Seq。l.将其规范为一个问答使命Mc Cann et a,Seq模子处理并利用Seq2;atching范式处置抽取式摘要Zhong et al.提出用M。
究进展显著虽然相关研,还很是初步但部门工作,键问题亟待处理仍然有良多关,题值得关心以下研究问:
输入端加强模子学问增广:从,体例是间接把学问加到输入有两种支流的方式:一种,原输入和相关的学问化的输入暗示另一方式是设想特定模块来融合。前目,在分歧使命上取得优良结果基于学问增广的方式曾经,答系统和阅读理解如消息检索、问。
rained Models)所谓预锻炼模子(Pre-t,事后锻炼一个初始模子即起首在一个原使命上,对该模子进行精调(Fine-tune)然后鄙人游使命(也称方针使命)上继续,使命精确率的目标从而达到提高下流。质上本, Learning)思惟的一种使用这也是迁徙进修(Transfer。而然,要人工标注因为同样需,规模往往也长短常无限的导致原使命标注数据的。么那,模的标注数据呢若何获得更大规?
天然言语处置行业成长的三大体素数据量、运算力和算法模子是影响。2年以来201,法的呈现推进了天然言语处置行业的快速成长数据量的上涨、运算力的提拔和深度进修算。、挪动设备的普及互联网、社交媒体,数据量急剧添加使发生并存储的,00亿的终端与设备联网2020年全球将有超5,将大于40泽字节发生的数据总量,量估计达1.5GB人均每天发生的数据。达到全球数据总量的20.0%中国2020年的数据总量将,8.4亿个增加至35.0亿个联网设备估计从2016年的,发生了大量的使用数据毗连设备数的快速增加。于优化天然言语处置算法数据的迸发式增加有助,法模子完成高效精准的识别锻炼海量优良的场景数据可以或许协助算。
理研发企业供给根本设备平台云办事供应商为天然言语处,的数据存储、运算以及挪用问题处理天然言语处置手艺研发厂商。摆设体例等要素因为性价比、,业较多选用公有云办事天然言语处置研发企。
的焦点在于将布局化的语义暗示序列化此中基于序列到序列的语义阐发方式,一系列的语义单位把语义暗示当作。组合法则的方式比拟基于文法和,q方式很是简单Seq2Se,到端的是端,工设想特征不需要人,文法和组合法则也不需要进修。而然,法也忽略了一个问题Seq2Seq的方,机械翻译分歧于,言不是一种天然言语语义阐发的方针语,形式化言语而是一种,条理布局它具有,单地将语义暗示偏平序列化Seq2Seq方式只是简,的条理布局消息忽略了语义暗示,于此基,出了Seq2Tree的方式Dong et al.提,条理化的解码器其焦点是一个,平化的语义暗示序列解码时不再生成偏,构化的语义暗示而是生成条理结,言之简而,的形式来表征语义用一个条理树布局,化时序列,广度优先遍历的形式采用条理布局树的。法都忽略了语义暗示token之间的慎密联系考虑到Seq2Seq和Seq2Tree方,一种Seq2Action的方式Chen et al.提出了,图作为语义暗示该方式采用语义,进行原子级分化然后将语义图,来暗示语义图的建立用设想好的动作序列,模子框架来生成动作序列进而用编码器-解码器,之间具有严酷的句法和语义束缚并操纵到语义暗示token,限的解码方式提出了一种受。方式因为其简单而无效的特点基于序列到序列的语义阐发,范畴最常用的基线模子成为了目前语义阐发。
天然言语处置手艺方面堆集深挚天然言语处置手艺研发企业在,B端营业市场拓展了不变的,狗和科大讯飞典型代表有搜。如例,硬件语音交互处理方案科大讯飞推出完美智能,、语义理解等手艺研起事题协助企业用户处理语音交互。定制化需求高B端市场的,发能力以及资金投入要求高对天然言语处置厂商的研,处置创业企业难以大范畴拓展B端市场导致缺乏资金、手艺堆集的天然言语。
搜狗兼顾所推出的AI主播“姚小松”央视财经与搜狗合作操纵搜狗知音的,姚雪松的抽象和声音是基于央视掌管人,成的仿真AI主播用人工智能手艺合。播的背后AI主,手艺仿照实在掌管人的声音是搜狗兼顾通过语音合成,音转化手艺通过文本语,的主播发声实现真人般,上的模子优化并连系平台,等与真人完全吻合使唇形、面部脸色,的“克隆”实现主播。小松”外除了“姚,播不只在传媒范畴被普遍使用同样基于搜狗兼顾的虚拟主,办事范畴都有相关使用案例还在教育、金融以及社会。
消息异构,体和关系本身消息之外在学问图谱中除了实,他类型消息还包含其,束缚、关系路径、视觉消息等如文本描述、实体属性、类别。体和关系的学问语义暗示操纵这些额外消息加强实,码和异构消息融合等问题次要挑战在于异构消息编。示和学问暗示结合进修的同一模子KEPLER给出了预锻炼言语表,所示如图,消息更好的嵌入到预锻炼言语模子中其通过结合进修不只可以或许将现实学问,获得文本语义加强的学问暗示同时通过预锻炼言语模子能够。
力方面运算,FPGAGPU、,用芯片的呈现ASIC等专,数据处置速度难题缓解了天然言语,芯片算力不足问题处理保守的CPU。IC等具有优良的并行计较能力新兴的GPU、FPGA、AS,幅优于CPU芯片机能大,强数十倍以至百倍算力比CPU芯片,型运算时间缩短了模,模子的前进速度加速使得天然言语运算。
用环境复杂天然言语使,同专业的天然用语差别较大分歧场景、分歧语种、不,言处置条理分歧所需要的天然语,天然言语处置模子不具通用性基于某一范畴语料库成立的,处置成果较着较差使用于其他范畴时,显著下降系统机能。然言语产物在分歧使用范畴的推广天然言语模子不具通用性限制了自,处置行业的成长历程大幅减缓了天然言语。
司成立于1999年科大讯飞股份无限公,片产物开辟、语音消息办事及电子政务系统集成的国度级骨干软件企业是一家专业处置智能语音及言语手艺、人工智能手艺研究、软件及芯。音与人工智能财产带领者科大讯飞作为中国智能语,言语处置等多项手艺上具有国际领先的功效在语音合成、语音识别、白话评测、天然。
的NLP基于学问,、常识学问图谱等)提拔NLP模子言语处置能力的相关处置方式是指操纵人类各类型布局化学问(如言语学问图谱、世界学问图谱。化学问及其带来的认知推理能力通过融合符号暗示的人类布局,的可注释性与认知推理能力付与言语深度进修模子更好,临的可注释性差、可扩展性差和鲁棒性差等瓶颈问题冲破当前NLP范畴中普遍利用的深度进修手艺所面。
有可编程性FPGA具,对FPGA电路进行快速烧录设想者可按照需要的逻辑功能,其出厂设想从而改变,性强矫捷。计布线相对固定但FPGA的设,芯片逻辑资本相对固定各类型号的FPGA,芯片的逻辑资本上限选定了型号即决定了,加运算能力无法随便增。
子使命:关系预测和三元组抽取关系抽取(RE)次要有两个。lass范式处理前者次要通过C,利用Seq Lab范式提取实体尔后者常以流水线体例处置:起首,范式预测实体间关系再利用Class。q2Seq范式处置三元组抽取使命Zeng et al.利用Se,用MRC范式处置RE使命Levy et al.使。外此,多轮对话后用MRC范式处置三元组抽取也能够通过转化为。
预测两个文本语义相关性的一种范式婚配范式(Matching)是。述为𝒴=CLS(ENC(𝒳𝑎Matching范式能够简单地表,�))𝒳�,是被预测的两段文本𝒳𝑎和𝒳𝑏,离散或持续的𝒴能够是。
量的辞书和言语模子的识别问题思必驰语音识别手艺处理了大,征提取的方式采用了鲁棒特,声情况下的错误率可以或许无效降低噪,一的模子合用于各类噪声情况并用动态噪声自顺应来使统,同口音通俗话识别支撑全国各处所不,利用情况下在用户现实,能连结较高水准引擎的识别率。
天然言语处置手艺研发企业以及天然言语处置创业企业中国天然言语处置市场参与者可分为互联网巨头企业、,处置行业占领约80%的市场份额此中互联网巨头企业在天然言语,业企业合计共占20%的市场份额天然言语处置手艺研发企业以及创。
是词性标注和词义标注词法阐发的次要使命。的根基属性词性是词汇,中判断并标注各词的词性词性标注是在给定句子,的词性复杂难以确定而兼类词和未登录词,词性是词法阐发的主要使命标注兼类词与未登录词的。境中明白各词的词义词义标注是在具体语,有多种意义如多义词拥,达的意义是可确定的但在具体语境中表。词的义项问题是词义标注的重点在分歧的具体语境中处理多义。
示的学问图谱离散符号表,下和数据稀少等挑战问题在计较上具有计较效率低。年来近,习的KRL的手艺方案人们提出了基于深度学,研究与使用并被普遍。
深挚的资本堆集互联网巨头有,实力雄厚手艺研发,将持久由互联网巨头主导天然言语处置手艺的迭代。研发多以营业结构为导向然而互联网巨头的手艺,不包含的范畴旗下产物生态,一般不会涉足互联网巨头,企业以及创业企业留下市场空间因而为天然言语处置手艺研发,创业企业能从细分范畴开辟市场天然言语处置手艺研发企业以及,头企业的间接合作避开与互联网巨。
是生成意义暗示并将这些意义指派给言语输入的过程语义阐发(semantic analysis)。入的粒度分歧按照言语输,析、句子级语义阐发和篇章级语义阐发语义阐发又可进一步分为词汇级语义分。常通,何区分和获取单个词语的语义词汇级语义阐发次要关心如,nse Disambiguation典范使命是词义消歧(Word Se,D)WS,的语境中即在特定,义词的准确词义识别出某个歧;析由词语所构成的句子的语义句子级语义阐发次要关心释,浅层语义阐发和深层语义阐发按照阐发的深浅程度又分为,Semantic Role Labeling此中浅层语义阐发的典范使命是语义脚色标注(,L)SR,及谓词的响应语义脚色成分即识别出给定句子的谓词。义阐发深层语,语义解析又称为,机可识别、可计较的语义暗示即将输入的句子转换为计较,使用情境的分歧语义解析又按照,ge to code)和言语到机械操作指令(language to instruction)可分为天然言语到布局化查询(language to query)、言语到代码(langua;并理解各个句子的语义以及句子与句子之间的语义关系篇章级语义阐发次要关心由句子构成的篇章的内在布局,个篇章的语义进而理解整。、篇章语义阐发的根本词语级语义阐发是句子,篇章语义阐发的根本句子级语义阐发又是。
、语义理解、语音合成、声纹识别等分析语音手艺思必驰具有自主学问产权的人机对话、语音识别,术不克不及很好支撑复杂语音交互功能的难题其智强人机对话手艺冲破了保守语音技,限于机器简单的句式使语音输入不再局,白话交换的环境下在复杂情况和天然,度和稳健的人机对话机能能包管优异的语音阐发精。或不精确的语音识别成果进行智能语义推理其智强人机对话手艺可以或许供给基于不完整,对话行为、对话形态和对话上下文的统计建模通过针对特定范畴特定使用需求、对话方针、,法笼盖现实对话形态的问题处理保守系统设想中法则无,果和错误推理成果的自顺应性同时加强系统对于错误识别结,的语音交互体验大幅度提拔用户。
根本设备公司为主以芯片或硬件等,设备切入从根本,术能力提高技,财产链上游拓展向数据、算法等。
端的语音交互手艺支撑思必驰为用户供给挪动,id、iOS等系统合用于Andro,能客服、地图导航等范畴可使用于语音助手、智,成以及语义理解等多种能力具备语音叫醒、识别、合。载场景中在智能车,“云+端”处理方案思必驰为用户供给,镜、智能车机、便携式导航仪等设备操纵智能语音操作系统节制智能后视,手解放实现双。
先行者为主以垂直范畴,用、面部识别使用等)堆集大量用户和数据在垂直范畴依托杀手级使用(如出行场景应,通用手艺和算法并深耕该范畴的,如滴滴出行、旷视科技等)成为垂直范畴的倾覆者(。
数据中复杂的言语现象为了可以或许描绘大规模,进修模子容量足够大还要求所利用的深度。模子显著地提拔了对于天然言语的建模能力基于自留意力的Transformer,程碑意义的进展之一是近30年来具有里。忍的时间内要想在可容,规模的Transformer模子在如斯大规模的数据上锻炼一个超大,为代表的现代并行计较硬件也离不开以GPU、TPU。以说可,模子完全依赖“蛮力”超大规模预锻炼言语,大计较资本的加持下在大数据、大模子和,取得了长足的前进使天然言语处置。推出的GPT-3如Open AI,具有1是一个,数的庞大规模750亿参,特定使命的锻炼无需接管任何,(如问答、气概迁徙、网页生成、主动编曲等)便能够通过小样本进修完成十余种文本生成使命。前目,天然言语处置的新时代预锻炼模子曾经开启了。
C端翻译、智译APP办事以及可穿戴式翻译产物新译科技次要向小我消费者供给在线文档翻译、P。文本的多种言语智能翻译智译APP可实现语音和,、住宿、商务等范畴合用于旅游、社交。文档格局输入在线种常用,业范畴的文档翻译可使用于通用或专,量较高翻译质。
进行阐发以获得句子的句法布局句法阐发旨在对输入的文本句子。句法阐发和成分句法阐发常见的句法阐发有依存。词与词之间的彼此依存关系依存句法阐发识别句子中,中的条理化短语语法布局而成分句法阐发识别句子。处置下流使命中都有使用句法阐发在诸多天然言语,实体识别使命中例如在嵌套定名,在彼此嵌套现象因为实体间存,的条理化短语语法布局配合建模因而很是适合和成分句法阐发中。
调集中查找用户所需消息的过程消息检索是计较机自主从文档。以及组织拾掇后具有于数据库中消息检索系统将消息标引、描述,数据库中消息的标引词婚配将用户输入的检索环节词与,消息检索要求实现用户的。用户输入的天然言语消息消息检索要求计较机理解,据库中的标引消息进行比对主动将天然言语消息与数,检索使命以告竣。用户输入的天然言语环节词如谷歌搜刮引擎可通过理解,检索方针页面列表反馈给用户一个,本人消息需求的页面加以浏览用户可在列表当选择可以或许满足。键词表达体味用户真正的查询企图由于搜刮引擎无法通过简单的关,成果调集以列表的形式供给给用户只能将所有可能满足用户需求的。
额外的预测方针和束缚函数学问束缚:操纵学问建立,原始方针函数来加强模子的。如例,开导式标注语料作为新的方针近程监视进修操纵学问图谱,列NLP使命并普遍用于系,系抽取和词义消歧照实体识别、关。建额外的预测方针或者操纵学问构,RNIE好比E,KEPLER等工作Co LAKE和,建立了响应额外的预锻炼方针都是在原始的言语建模之外。
统行业公司为主以创业公司和传,或行业数据基于场景,分场景使用开辟大量细。
外此,交换过程中人类在言语,如婴儿、小孩以及成人代表分歧春秋段人群)利用的话语表达内容凡是暗含常识性暗示(,用语者的个性化特征话语表达气概反映,容可有分歧的表达体例分歧的人对不异的内。能处理常识问题和个性化问题现阶段的天然言语处置模子未,查找附近的餐馆”指令时如手机语音助手听到“,找附近餐馆的使命可在地图上施行查,近餐馆消息并显示附,者说“我饿了”但若发号指令,不会有任何反映手机语音助手则,饿了需要进食”的常识由于语音助手缺乏“,我饿了”的话语而人类听了“,“需要进食”反映必然是。类认识中的常识浩繁躲藏在人,备且无法进修计较机并不具,在机械问答和机械搜刮中的结果若何模子开辟者亦不晓得将常识学问用,立常识学问库业内尚待建,练模子测试训。
晚期在,的消息抽取系统)都采用基于法则的方式大部门消息抽取系统(如MUC评测中,人工制定法则该类方式依托,预判和注释其长处是可,移植性差但面对着,无法总结无效的法则良多场景很难以至。年代以来自90,息抽取的支流方式统计模子成为信,文本输入到特定方针布局的预测凡是将消息抽取使命形式化为从,输入与输出之间的联系关系利用统计模子来建模,法来进修模子的参数并利用机械进修方,F)将实体识别问题转化为序列标注问题典范的方式包罗利用前提随机场(CR。年来近,习时代到临跟着深度学,神经收集主动进修有区分性的特征研究者次要聚焦于若何利用深度,具抽取特征时具有的错误累积问题进而避免利用保守天然言语处置工。究的深切跟着研,练言语模子的引入出格是大规模预训,在公开数据集上达到了不错的成就基于深度神经收集的消息抽取模子,景结果还不尽人意可是在现实使用场。
词法、句法、语义等阐发问题主动问答使用涉及天然言语的,成手艺使用的集中表现是天然言语理解与生。回覆用户提出的问题主动问答系统能主动,然言语表述的谜底反馈给用户基于自,词婚配排序的文档列表不再是简单的基于环节,要准确理解用户所提出的问题系统在生成谜底的操作中需,中的环节消息抽取用户问题,料库或学问库进而检索语,然言语的形式反馈给用户将可婚配的最佳谜底用自,问答使命完成主动。
识别以及图像识别分歧天然言语处置与语音,单轮处置操作过程天然言语处置不是,行单轮阐发无法输出成果算法模子对单一输入进,文或前后轮对话语境相关天然言语的语义与上下,行多轮阐发方可获得成果需要对输入的天然言语进。度进修手艺而目前的深,展并不成熟多轮建模发,阐发模子的成熟度无法相提并论与语音识别以及图像识此外单轮。
络模子兴起之前在深度神经网,组合法则的模子占领支流语义阐发范畴基于文法和。年来近5,络模子的兴起跟着神经网,q)在天然言语处置多个使命上的成功出格是序列到序列模子(Seq2Se,器翻译如机,阐发问题建模为序列到序列的问题语义阐发使命上也起头测验考试将语义。2年近,的大规模预锻炼言语模子的提出跟着像BERT、GPT如许,个使命上面取得SOTA并在天然言语处置的多,预锻炼+精调的新研究范式整个NLP范畴都转型采用。大模子里面的学问为了更好的操纵,语(prompt)的方式海潮NLP范畴还兴起了基于提醒。跟整个NLP范畴的大潮深度语义阐发范畴也紧,面向语义阐发的预锻炼方式和基于大模子受限生成的方式与之对应的先后呈现了基于序列到序列的语义阐发方式。
前目,限解码在语义阐发问题上的能力研究者都已认识到大模子加受。需要人工参与但整个过程还,要人来参与设想如束缚前提需,相转换的同步文法需要人工定义用于典范句式与语义暗示之间互。部门交给模子自主进修若何将这些人工参与的,的soft的前提束缚是下一步可研究的点实现自进修的soft的同步文法和自进修。
等人工智能的成长需求为满足天然言语处置,度进修的芯片部门针对深,PU和BPU等接踵面世如TPU、NPU、D,及机能限制但受场景以,芯片成长尚未成熟公用的人工智能。佳芯片方案仍以GPU为主导目前天然言语处置运算的最。
公司为主以软件,和通用手艺平台深耕算法平台,用作为流量入口同时以场景应,soft、IBMWatson等)逐步成立使用平台(如Micro。
电子病历输入系统落地上海瑞金病院科大讯飞操纵讯飞开放平台开辟语音,端大夫佩带的麦克风硬件对接通过将天然言语处置手艺与前,自大夫和患者交换过程中的语音消息在大夫随身佩带麦克风时可以或许阐发来,关的闲聊语句主动过滤无,化的录入病例表格并将病情消息布局,环境下一般,问完诊大夫,根基完成了病历记实也。的语音电子病历系统基于讯飞开放平台,0%的病历书写时间总体上节流大夫4。1分钟400字该系统输入高达,万级医学词汇且系统内置百,符号的口述或主动生成支撑40种以上的标点。
言的具体使用语用指人对语,涵养、言语行为、设法和表达企图亲近相关天然言语用语与语境、言语利用者的学问。语境中研究阐发言语利用者的表达意图语用阐发是计较机在情景语境和文化。
一步提高词法阐发和句法阐发模子的表示结合建模:为领会决错误传布问题、进,注和句法阐发进行结合建模一个常见方式是将词性标。来说具体,成分句法阐发这三个使命中词性标注、依存句法阐发和,务均可组合起来进行结合建模肆意两个使命或者全数三个任。员发觉研究人,与建模的各个使命的精确率结合建模能够无效提拔参,如例,行依存句法阐发和成分句法阐发的结合建模Zhou et al.在宾大树库长进,零丁建模削减了16%和3%在两个使命上的错误率别离比。
模子编码,编码利用的具体模子架构即对实体和关系的交互,分化模子和神经收集模子包罗线性/双线性模子、。到接近尾部实体的暗示空间中线性模子通过将头部实体投影,性/双线性映照将关系表述为线,istMult代表方式有D,lEx等Comp。解为低秩矩阵以进行表征进修分化模子旨在将关系数据分,L、Tuck ER等代表方式有RESCA。收集布局对关系数据进行编码神经收集模子通过用更复杂的,KG-BERT等如R-GCN、,T自创PLM思惟此中KG-BER,体和关系的编码器用BERT作为实。
为两种:基于转移的方式和基于图的方式句法阐发:支流的句法阐发方式次要分。转移操作来建立合法的句法树布局基于转移的方式通过预测一系列,栈区(期待输入的文本序列)和曾经预测出来的转移操作序列这种方式需要同时建模缓存区(曾经生成的部门树布局)、堆,模方式为stack-LSTM此中常见的缓存区和仓库区的建,模方式常用LSTM转移操作序列的建;输入、给文本局部打分基于图的方式起首编码,算法来恢复句法树布局尔后采用动态规划等,STM和Transformer该种方式采用的支流编码器包罗L,法阐发)或CKY算法(成分句法阐发)解码器一般基于最大生成树算法(依存句。年来近几,练言语模子的呈现跟着大规模预训,模子也常被用作句法阐发器的编码器BERT、XLNET等预锻炼言语。阐发器是基于图的方式当前最佳的依存句法,尼亚大学树库数据集上取得了跨越96%的有标签F-1分数利用BERT后能够在基于《华尔街日报》来标注的宾夕法;亦采用了基于图的方式最佳的成分句法阐发器,库上取得了接近96%的F-1值在利用BERT的环境下在宾大树。同时与此,型架构、转移范式不竭出现句法阐发范畴也有新的模,如例,以批处置的基于CRF的成分句法阐发器Zhang et al.提出了一种可,ach)和并列(juxtapose)的新转移范式Yang et al.提出一种基于保持(att。
解成果不精确天然言语理,处置使用推广限制天然言语。、大数据等手艺指引下发生的机械行为天然言语理解与生成是机械在人工智能。化布景和人类风尚习惯学问储蓄机械因为难以具有糊口常识、文,载体的天然言语对于作为文化,风尚习惯等要素阐发言语内容无法连系具体的言语情况、,机械地阐发源语的语法布局只能通过系统设定的法则,无法处置言语逻辑,层层句式嵌套的环境对于复杂句子布局或,理解精确度不高机械的天然言语。者的实在表达企图的能力无法在短期内获得较着提高机械对天然言语长句的理解能力以及全方位体味语用,理解能力比拟与人类的言语,具有较大差距仍然。完美部门范畴的学问库和语料库天然言语处置使用临时只能通过,言语处置使用的用户体验优化部门范畴内的天然。
、手艺、数据资本等实力互联网巨头企业通过资金,层、手艺层以及使用层全财产链结构实现天然言语处置的根本软、硬件,言语处置使用平台如百度开辟了天然,开源供给底层研发架构支撑为浩繁天然言语研发企业,算法、问答系统、阅读理解等焦点手艺同时百度自主研发天然言语处置根本,闻、百度翻译、百度助手等C端产物中并将焦点手艺使用于百度搜刮、百度新,品的智能程度提拔了自有产。
参数空间进行考量学问迁徙:则是从,指点的假设空间获取一个学问,型更无效从而让模。移进修和自监视进修别离关心从标注数据和无标注数据获取学问迁徙进修和自监视进修别离关心从标注数据和无标注数据获取迁。型学问的典型范式作为一个迁徙模,P使命都能够取得优良的结果微调PLM在绝大大都NL。息处置范畴在中文信,M也接踵被提出一些中文PL,2、Pan Gu-𝛼等如CPM-1、CPM-,务中展示了优良机能也都在各类中文任。
:(1)天然言语理解:计较机理解天然言语文本的思惟和企图天然言语处置机制涉及天然言语理解和天然言语生成两个流程;用天然言语文本表述思惟和企图(2)天然言语生成:计较机。
公司为主以互联网,础设备和手艺持久投资基,用作为流量入口同时以场景应,使用堆集,的使用平台成为主导,Amazon、Facebook、阿里云等)将成为人工智能生态建立者(如Google、。
法阐发使命上在词法和句,的范畴)内模子的表示接近理论上限跟着在旧事范畴(宾大树库所基于,同时也富有挑战性的跨范畴和多言语场景中去研究人员们将视线转向了愈加具有适用性、,来说具体,景下若何使得词法、句法阐发器仿照照旧得以使用研究人员们试图探究在低资本、零资本的情,研究标的目的沿着这个,域树库的建立和跨范畴、跨言语句法阐发器的建立等工作近期工作包罗了跨言语、跨范畴词法阐发器的设想、新领。
识次要是环绕实体、实体关系等相关现实学问图谱PLM的多元学问融合:目前在PLM中融合知,学问条理还比力单一融合的学问类型和,融合度低的问题具有学问指点。同类型的丰硕学问系统面向人类分歧条理不,学问的PLM框架和进修机制摸索融合这些多条理多类型,来研究的主要标的目的是PLM手艺未。
控制细分市场数据环节成功要素:,场景建立使用选择合适的,度的场景使用成立大量多维,用户抓住;时同,公司合作与互联网,业模式和人工智能无效连系保守商。
的模子本身的处置流程进行优化学问支持:关心于对带有学问。引入学问指点层来处置特征一种体例是在模子的底部,丰硕的特征消息以便能获得更。如例,PLM底部注入丰硕的回忆特征利用特地的学问回忆模块来从。方面另一,模子顶层建立后处置模块学问也能够作为专家在,确和无效的输出以计较获得更准。如例,进言语生成质量操纵学问库来改。
讯的人工智能尝试室AI Lab是腾,识别、天然言语处置、机械进修等研究范畴包罗计较机视觉、语音。理基于并行计较、分布式爬虫系其研发的腾讯文智天然言语处。
机主动阐发、表征人类天然言语的学科天然言语处置是通过建立算法使计较。解和生成天然言语的过程天然言语处置是计较机理,生成天然言语文本(包罗字、词、句和篇章)的能力天然言语处置手艺使计较机具有识别、阐发、理解和。
的数据集归纳出的识别逻辑算法是计较机基于其所锻炼,术更精准地舆解与生成天然言语文本算法模子的优化可使天然言语处置技。杂布局设想和各类梯度手艺深度进修算法通过利用复,变换成多个处置层将多重非线性布局,样本的笼统计较实现对大量数据,输入消息的函数模子拟合出一个可处置新,类或预测问题处理数据分。底子上改变了天然言语处置手艺的面孔基于深层神经收集的深度进修方式从,处置问题的定义改变了天然言语,理所利用的数学东西变动了天然言语处,保守浅层进修算法的局限深度进修的呈现冲破了,理算法的设想思绪重塑了天然言语处,言处置研究的成长极大地推进天然语。
ion)的方针是从非布局化文本中抽取出布局化的消息消息抽取(Information Extract,elation Extraction次要包罗实体抽取、实体关系抽取(R,nt ExtractionRE)、事务抽取(Eve,elation ExtractionEE)和事务关系抽取(Event R,)等使命ERE。本中名词性的短语实体次要是指文,名、时间、日期、数字等好比人名、地名、机构。 Entity Recognition实体抽取也称为定名实体识别(Named,R)NE,识别和分类包罗实体的。找出哪个片段是一个实体实体识别就是从文本中。出的实体属于什么类别实体的分类就是判断找,名、地名等好比:人。两个实体之间的语义关系实体关系抽取则是判断,个实体之间是“出生于”的关系好比“姚明”和“上海市”这两,”则是“首都”的关系而“北京”与“中国。别特定类型的事务事务抽取使命是识,定脚色的要素找出来并把事务中担任既,别、事务类型分类、论元识别和脚色分类使命该使命可进一步分化为4个子使命:触发词识。
、北京紫平方、追一科技、玻森数据、武汉狼烟普天、北京嘿哈科技、拓尔思(300229)、智言科技、明略数据、今日头条、姑苏驰声消息等中国参与者次要有:百度(09888)、科大讯飞(002230)、搜狗(00700)、云知声、新译消息、思必驰、智齿科技、达观数据。
析是一个条理化过程天然言语理解和分,层层递进:(1)词法阐发:阐发词汇的各个词素从词法阐发、句法阐发、语义阐发到语用语境阐发,言语学消息从中获得;析句子和短语的布局(2)句法阐发:分,的感化以及彼此间的关系识别各词语、短语在句中;布局意义及词与布局连系的意义(3)语义阐发:找出词义、,言所具有的外界情况对言语利用者所发生的影响确定言语所表达的线)语用语境阐发:阐发语。
手艺及机械进修引入客服产物智齿客服率先将天然言语处置,问题并婚配最佳谜底实现精准理解用户,率高达98%反馈谜底精确。服与人工客服自在切换模式智齿客服支撑的机械人客,服的同质化答复问题可处理80%人工客,主动组织尺度谜底同机会器人客服可,升客服答复质量和效率协助客服人员大幅提。
能成长的基石数据是人工智,工智能供给原材料海量数据为锻炼人。年来近,设的公共数据集不竭丰硕由学术及研究机构承担建,不竭提高数据质量,高智能模子的精确度利于人工智能企业提。如例,练的数据集类型不竭丰硕可使用于天然言语处置训,康奈尔片子对话语料库、经济旧事相关文章等言语调集接踵建成维基百科语料库、斯坦福大学问答数据集、亚马孙美食评论集、,语、当局用语等浩繁天然言语使用场景内容笼盖媒体用语、收集用语、片子用,处置分歧范畴天然言语的模子的精确度有助于天然言语处置研发企业优化用于。
出台相关法令律例及政策我国在人工智能范畴稠密,在人工智能范畴出台国度计谋能够看出去世界次要大国纷纷,代制高点的情况下抢占人工智能时,上升到国度计谋的决心中国当局把人工智能。
RL:言语学问图谱言语学问图谱的K,化言语表达的言语学学问描述的是以形式化和布局,各类NLP系统能够轻松植入,t、WordNet等代表性有How Ne。LP使命的根本步调词暗示进修是很多N,2Vec、GloVe等代表性方式有Word,个词映照成一个向量但这些方式都是将每,词多义的问题不成以或许处理一。该问题为处理,识图谱指点的词暗示进修很多学者提出操纵言语知,学问加强词的语义暗示通过其细粒度言语学。如例,的词暗示进修方式(SE-WRL)1)基于How Net义原编码,一组义原的组合将每个词当作,ip-gram词暗示进修进行结合建模将词义消歧和融合义原、义项、词的Sk。Retrofitting方式2)将词向量革新为语义辞书的,rdNet等语义辞书中的关系消息来细化向量空间暗示给出了通过激励链接词具有类似的向量暗示来利用Wo。型的布景暗示进修的兴起近几年跟着基于预锻炼模,言学问图谱加强词的上下文暗示相关研究起头聚焦于若何操纵语。
近最,sed tuning)敏捷风行起来基于提醒的微调(prompt-ba。之下比拟,没有获得充实的摸索其他潜在的同一范式。、MRC或Seq2Seq模子大概应遭到更多的注重通过预锻炼或其他手艺摸索更强大的Matching。
为文本指定预定义的标签分类范式(Class)。深度神经收集的编码器来提取特征文天职类凡是将文本输入一个基于,层分类器来预测标签然后将其输入一个浅,ENC(𝒳))如𝒴=CLS(。是独热编码𝒴能够,环收集或TransformersENC(⋅)凡是是卷积收集、循,的多层感知器和汇聚层实现CLS(⋅)常由一个简单。
言表达映照到方针学问布局上消息抽取的焦点是将天然语,算机处置的学问并转换为可供计。而然,样性、歧义性和布局性天然言语表达具有多,、开放性以及规模庞大的特点此中包含的学问具有复杂性,取使命极具挑战性进而导致消息抽。年代被提出以来自上世纪80,言语处置的研究热点消息抽取不断是天然。
看法挖掘)感情阐发(,的感情倾向(如客观/客观是计较机系统自主对文本,/消沉积极,行挖掘和阐发的过程喜好/厌恶等)进。家主动处置用户评论感情阐发能协助商,照排序法则进行展现将阐发过的评论按,告白营销结果协助商家获得,的商家在评论区可设置主动置顶反映积极情感的用户评论如淘宝、天猫等电商平台、携程、爱彼迎等旅游住宿平台,面消息的用户评论置后部门反映负,户眼球的结果达到吸援用。发布的消息领会用户爱好商家还可通过度析用户,准营销实现精,可按照用户颁发的微博如新浪微博上的零售商,解用户的小我爱好微话题等内容了,送优惠及新品消息为用户定制性的推。
020年截至2,模为118亿2000万美元全球天然言语处置的市场规,至530亿8000万美元估计将于2026年增加。阶段现,手艺贸易化并不成熟我国天然言语处置,客服、搜刮引擎等)均无法将收益间接归因于天然言语处置手艺部门已实现贸易化使用的天然言语处置手艺相关产物(如智能,文档分类、舆情阐发等)尚未发生较着受益零丁使用天然言语处置手艺的产物使用(,生的市场营收规模仍然较小因而天然言语处置手艺产,20年20,别为1512.5亿元和5725.7亿元我国人工智能焦点财产及带动财产规模分,98.1亿元和7442.1亿元估计至2021年将别离达到18,为32%和19.5%年均复合增加率别离。设备、智能机械人、智能助手等)不成或缺的焦点手艺但天然言语处置手艺是浩繁人工智能设备(如智能家居,智能化营业处置程度要求的提高跟着智能设备数量增加以及行业,无望获得进一步拓展天然言语处置市场,23年间以48.2%的年复合增速实现快速增加天然言语处置市场营收规模无望在2019-20。
用一个庞大的锻炼集锻炼的目前的小样本进修设定需要,way Kshot测试时只给出N-,本长进修并预测在这N*K个样。习不具有庞大的锻炼集实在场景下的小样本学,T3起头从GP,)进修范式遭到研究者的关心预锻炼-提醒(Prompt,建模成言语模子使命该范式将下流使命也,十条样本作为锻炼集在只给出几条或几,言模子中包含的大量学问借助与大规模预锻炼语,本进修结果取得了取得了不错的小样。外此,in+Finetune范式相对于保守的Pretra,有得天独厚的Prompt,数量对庞大计较资本的需求能够脱节指数级的预锻炼参,预锻炼模子高效的操纵。述阐发基于上,—提醒进修范式进行高效的小样本进修消息抽取的成长标的目的之一是操纵预锻炼。中消息抽取使命模板的设想具体包罗:1)提醒进修;动进修与挖掘2)模板的自;式进行消息抽取的理论阐发3)预锻炼-提醒进修范。
景、垂直细分的使用场景切入天然言语处置市场天然言语创业企业多以具体的天然言语处置场,业使用处理方案或消费级产物为下流用户供给单一类型的行,供特地的智能客服处理方案如智齿科技为企业用户提。
ab)可用于模仿各类使命序列标注范式(Seq L,实体识别(NER)和组块阐发如词性标注(POS)、定名。注模子由编码器息争码器构成保守的基于神经收集的序列标,�1如�,⋯,(ENC(𝑥1𝑦𝑛=DEC,⋯,�))𝑥�。�1�,⋯,是𝑥1𝑦𝑛,⋯,对应的标签𝑥𝑛。
、RNAV重估净资产估值法、EV/EBITDA估值法、DDM估值法、DCF现金流折现估值法、NAV净资产价值估值法等估值方式能够选择市盈率估值法、PEG估值法、市净率估值法、市现率、P/S市销率估值法、EV/Sales市售率估值法。
较强的手艺劣势新译科技具有,梅隆大学LTI尝试室以及新译-澳大-清华人工智能研究院四所优良天然言语研究尝试室供给的手艺人才和原创手艺支撑同时具有澳门大学天然言语处置与葡中智能翻译(NLP2CT)尝试室、葡萄牙里斯本L2F语音尝试室、美国卡耐基,017年通过国度科技功效认定公司所研发的智能翻译产物于2,吴文俊人工智能科学手艺奖并获得深圳青年手艺奖以及。有近百人的团队新译科技目前拥,华大学天然言语处置研究核心焦点手艺研发人员次要在清,器翻译的各个衍生品澳门团队次要开辟机,言语处置底层设想深圳团队做天然,端、产物和发卖北京团队担任前。翻译程度、提高语义翻译的手艺、改良主动批改手艺提高后编译能力程度新译科技将来将会出力提拔限制性神经收集翻译手艺、加强交互式辅助。
取还面对着复杂的语境实在场景中的消息抽,是通过多个句子表达的例如大量的实体间关系,多个事务彼此影响统一个文档中的,近也收到普遍的关心文档级的消息抽取最,分布在文档中分歧位置的实体的消息代表性的方式是利用图神经收集融合,进行消息的传送并操纵图算法。测验考试建立文档级图Quirk等最早,子之间的关系捕捉相邻句。体提及(Mention)和句子为节点的文档图Christopoulou等建立以实体、实,到边的暗示进行关系分类并通过图上的迭代算法得,用雷同的方式对文档建模之后有大量的研究者采。图收集外除了利用,用大规模言语模子建模文档研究者也起头测验考试间接使,统一个实体编码作为实体布局消息送入到BERT编码层Xu等将Mention能否在统一个句子中、能否指向。替用于多标签分类的全局阈值Zhou等提出自顺应阈值代,找到有助于确定关系的相关上下文特征并间接操纵预锻炼模子的自留意力得分。言语模子的研究上在大规模预锻炼,入学问加强语义暗示研究者也测验考试着加,三个级此外遮罩(MASK)锻炼例如ERNIE中字、短语和实体,、关系判别作为辅助使命协助模子的锻炼Qin等通过对比进修的体例将实体判别。
的预锻炼模子方式雷同与其它面向特定使命,环节:收集数据和设想自监视进修使命面向语义阐发的预锻炼模子也包含两个。sql的语义阐发问题针对text-to-,型是GraPPa典型的预锻炼模,-to-sql问题的数据收集方式其采用了两种常用的用于text,数据中抽取表格与天然言语对一是从已有的跟表格相关的,样的表格上主动生成(表格二是操纵同步文法在新采,言语天然,)数据对sql。于预锻炼言语模子的输入预锻炼模子的输入分歧,询与表格的表头拼接起来的这里的输入是将天然言语查。习使命方面自监视学,然言语词语与表头的交互为了在暗示层面简历自,码使命设想掩,行随机的掩码即对输入进,行回复复兴再进,丧失函数最初计较。暗示层面进修表为了进一步在,语义标签来实现通过预测表头的。锻炼模子因为是预,用BERT一样便利利用方面能够像使,语义阐发模子可合用于所有。
产物包罗软件和硬件产物新译科技的B端和G端,体及当局机关等企业和当局机构供给办事次要面向大型央企、军工企业、互联网媒。
Vite、Open KE、DGL-KE等系统东西更大规模的学问暗示:虽然曾经呈现了Graph ,针对小规模学问图谱但这些东西还次要,识图谱的使用潜力这限制了大规模知。的规模越来越大目前学问图谱,跨越9万万实体、14.7亿的关系如Wiki data曾经含有了,呈现快速增加趋向并且这种规模仍然。亿级实体规模的图谱上仍然是一个挑战若何将现有学问暗示进修方式适配到。
游市场主体为各类型用户天然言语处置财产链下,户和小我用户包罗企业用。采办行业使用企业用户次要,析产物、文天职类产物等如智能客服产物、舆情分,务处置的智能化程度协助企业用户提拔业。言语处置厂商合作的核心目前的B端市场是天然,情阐发产物等)测验考试了贸易化运作部门使用产物(如智能客服、舆,馈优良市场反,市场成长并未成熟但浩繁细分范畴,仍待挖掘市场空间。译软件、消息检索以及互联网搜刮等办事小我用户次要利用手机语音助手、机械翻。产物较多是天然言语处置厂商免费供给的小我用户利用的天然言语处置手艺使用,C端市场开辟清晰的贸易模式天然言语处置厂商遍及未在。
大量计较能力投入环节成功要素:,质多维度数据堆集海量优,手艺平台和使用平台成立算法平台、通用,用为入口以场景应,用户堆集。
过Class范式很好地处理保守的文天职类使命能够通。分类)可能具有挑战性但其变体(如多标签。此为,采用Seq2Seq范式Yang et al.,使命中标签之间的彼此感化以更好地捕获多标签分类。ching范式预测输入对(𝒳Sun et al.采用Mat,)能否婚配𝐿𝑦,原文本𝒳是,类𝑦的描述𝐿𝑦是。
前目,引了国表里多量学者语义阐发的研究吸,子级语义阐发标的目的上但大部门都集中于句,的研究工何为少词汇级和篇章级。汇级语义阐发次要由于词,义消歧如词,展多年已发,趋成熟手艺已,句子级的语义阐发研究的重心转向;全体的篇章理解过于坚苦而篇章级语义阐发因为完,与之相关的使命因而衍生了多个,割、指代消解、共指消解等如篇章的布局阐发、话语分,且偏边缘使命分离,研究关心很少导致获得的,也迟缓进展。来说全体,取得了必然的进展语义阐发虽然已,未成熟完满但手艺还远。
于2007年思必驰成立,手艺的智能语音办事商是研发智能语音交互,天然言语交互处理方案为企业和开辟者供给,人机对话操作系统、人工智能芯片模组等包罗DUI开放平台、企业级智能办事、。完成由元禾控股、中民投领投思必驰已于2018年5月,投的5亿元人民币D轮融资深创投、富士康、联发科跟。
RL:世界学问图谱世界学问图谱的K,实体及其关系的学问库指以布局化符号暗示的,ta、DBpedia等代表性有Wiki Da,实体和关系的低维分布式暗示其暗示进修的焦点问题是进修。)若何怀抱现实三元组的合理性相关研究环绕的焦点问题有:1;型建模关系交互2)何种编码模;合异构消息3)若何融。
取的海量通用文本语料锻炼获得目前PLM次要采用互联网获,富语义模式的编码实现了对文本丰,使用布局化学问但因为没有盲目,识使用和推理能力仍然严峻缺乏知,性和鲁棒性缺乏可注释。此为,学问的PLM及其进修框架很多学者研究了融合布局化,分为以下4种融合方式大致:
使命的通用框架范式是建模一类。former同一以及大规模预锻炼模子的普及过去几年跟着神经收集架构逐步向Trans,务的建模曾经收敛到几种支流的范式大大都天然言语处置(NLP)任。
)是一种细粒度的感情阐发方面级感情阐发(ABSB,以被分歧的范式处置能够分为7种子使命。C范式处置所有的ABSB子使命Mao et al.采用MR。将使命的标签转化为词元序列Yan et al.通过,Seq范式来处置再利用Seq2。
定单词序列出此刻句子中的概率言语模子范式(LM)估量给。�𝑘=DEC(𝑥1它能够被简单暗示为�,⋯,�−1)𝑥�,何自回归的模子DEC能够是任。𝑥=DEC(ENC(𝑥̃))一种LM的变体ML能够被规范为:,n)替代为特殊词元[MASK]获得𝑥̃由将𝑥的一些词元(toke,预测的词元𝑥暗示待。
理手艺的深切成长跟着天然言语处,保守行业实现更深条理的连系天然言语处置使用无望与更多,多人工智能效应为人类带来更。
前目,链资本劣势拓展大公有云办事行业的企业公有云办事供应商有:①通过云办事财产,运营商如电信,备制造商收集设,厂商等IDC,较强的资金实力此类企业具有,有云财产链上游加上本身处在公,面劣势较着根本设备方;联网企业②大型互,马逊如亚,里巴巴等腾讯、阿,金实力雄厚此类企业资,可度高客户认,、手艺成熟设备齐全,营业的有益前提具备成长公有云;软件企业③保守的,、Oracle、金蝶等如Microsoft,品的市场承认度高此类企业的软件产,累丰厚手艺积,源丰硕客户资,有云市场拓展有益于向公。之外除此,新兴的创业公司行业中具有不少,oud、七牛云等如青云、Ucl。
律范畴在法,索、判决预测、法令文书主动生成、法令文本翻译等天然言语处置使用可协助法令从业人员进行案例搜,件预处置实现事,案件处置花费时间削减从业人员相关。疗范畴在医,断等医疗步调可由相关天然言语处置使用辅助进行病历的辅助录入、医学材料的检索与阐发、辅助诊。料浩如烟海现代医学资,、方式成长迅猛新的医学手段,控制所有的医学成长动态大夫和专家无法及时完全,精确地寻找各类疑问病症的最新研究进展相关天然言语处置使用可协助大夫快速,供及时无效的参考为大夫的诊断提。
字典中最常见的词性作为当前词的词性词法阐发:最简单的词性标注器是利用,决大约85%的词性标注问题但这种简单的法则只能够解。性歧义的问题为领会决词,习算法进行词性预测研究者们利用机械学。方式的时代在基于统计,提取字词特征研究人员手动,前缀、后缀等特征例如字母大小写、,模子计较可能的标签序列的概率分布并利用隐马尔可夫、前提随机场等,签序列作为输出并选择最佳标。收集时代后进入神经,former等编码器对输入文本进行编码常见的做法是利用LSTM、Trans,或者CRF进行解码预测并利用Softmax,J数据集上取得了跨越97%的精确率这种方式在基于《华尔街日报》的WS。年以来近几,升机能和鲁棒性为了进一步提,开编码长距离标签依赖关系等工作研究人员测验考试在词性标注模子上展。
在text-to-text使命上的成功基于大模子的受限生成的方式开导于像T5,生成使命上的成功以及GPT在文本。xt问题的分歧:语义阐发生成的不是天然言语考虑到语义阐发使命与text-to-te,的语义暗示而是形式化,定的文法束缚需要满足一,两头言语:典范句式研究者们引入了一种,与语义暗示之间的一种言语它是一种介乎于天然言语,言语雷同又与天然,定性的文法但又合适确,同步文法进行确定性的转换它与语义暗示之间能够通过。典句式基于经,一种受限的复述生成语义阐发能够转换成。输入句子即给定,生成其典范句式大模子操纵复述,操纵束缚来减小解码空间在解码生成过程中能够。解码过程中束缚简直定这类模子的环节在于,于文法的形式引入束缚前提目前一般采用开导式的基。大模子因为,ot和zero-shot问题上都表示超卓如T5、BART和GPT在few-sh,shot和无监视的设定下也取得了很好的成就基于大模子的受限生成语义阐发方式在few-。
语法布局或句子中词汇间的依存关系句法阐发的根基使命是确定句子的,言的语法系统包罗确定语,言语单元内成分间的依存关系推导句子的句法布局明白合适语法法则的句子的语法布局以及通过度析。
2017年成立人工智能委员会国际化尺度化组织(ISO)于,庇护等范畴的尺度研制工作担任涵盖算法成见、隐私。出了“人权、福祉、问责、通明、慎用”的五项准绳电气和电子工程师协会(IEEE)在2017年提,响的AI伦理准绳之一已成为国际上最具影。术界在学,18年配合发布《人工智能的恶意利用:预测、防止缓和解》牛津大学、剑桥大学和Open AI公司等7家机构于20,的平安要挟并提出应对建议阐发了人工智能可能带来。业界在企,制定了人工智能开辟的伦理准绳微软、谷歌、IBM等科技企业,黑工业大学成立了AI伦理研究所脸书也在2019岁首年月结合慕尼。
翻译插件和网页翻译插件②智能翻译插件包罗办公,ffice两大办公系统上利用办公翻译插件能够在WPS和O,的快速转换和阅读满足多言语文档;各大浏览器网页翻译网页翻译插件支撑,母语阅读一键转化。
智能计较能力的新型芯片环节成功要素:开辟具有,音识别芯片等如图像、语,的使用场景拓展芯片;办事器、无人机(车)在挪动智能设备、大型,施上普遍集成使用机械人等设备、设,本的运算能力、办事供给愈加高效、低成,进行深度整合与相关行业。
|
 返回首页
返回首页 
 栏目文章
栏目文章