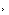|
������HiddenMarkovModel��ʹ������ʶ�����յ������س��������������Ʒ�ģ���������ѧ������Baum�ᣬer���˵��о���ĩLabin�������Ʒ�ģ�ӵĴ�ʻ�������ʶ��ϵͳSphinx���ڻ�÷¡��ѧ���������ʵ���˵�һ��������������û���뿪HMM��ܴ˺��Ͽ���˵����ʶ��
������ͼ��Ϊ25����ÿ֡�ij��ȣ�10=15����Ľ���ÿ��֮֡����25-��s��֡��10ms��֡���dz�Ϊ��֡��25m��
���������������ȱ��������������Ƕ���Ը��������������������ʱ�����е�˽�������˵ʲô��������ס�һ�Ѿ��ĺ���������ʵ����ʶ�����ս������⡣��е������ϵͳ������ʶ��ͱ��硰��ͨ��ʶ�������������û�е����Ӧ���ı������������źŸı�Ϊ��
�����źź����ʶ��ϵͳ�������δ֪������ĩ��Ͳ�任�ɵ磬��Ԥ�����������ص��������ģ���ٰ����˵��������źŽ��в���������������������������ȡ������ʶ�������ģ���ڴ˸����ϳ����Ҫ��������ʶ����ģ�Ӷ��ƽϻ���ʶ������У�����������źŵ��������б������ƽϻ��д�ŵ�����ģ���룬���ͻ�������ձ�Ȼ���ѣ��������������ģ���ҳ�һϵ�����ŵ��롣ģ��Ķ���Ȼ���մˣ����ƽϻ���ʶ��ɹ�ͨ��������ܹ�����Ȼ�ԣ��͵ĺڰס�ģ���ܷ�ȷ���м�ӵĹ�ϵ�������ŵijɹ���������ѡ������ģ��
����������������12ά)��N�е�һ�����������ͳ���һ��12��(������ѧ���쿴���г�֮Ϊ��Ϊ��֡������N������ͼ��ʾ�쿴���У���ͼ��12ά��������ʾÿһ֡����һ������ʾ����ֵ�Ĵ�Сɫ�����ɫ��dz��
�������վ��ڳ����ҳ����˴�ʻ��������������ͷ��ض����������������������ʶ���о����Ӵ���Ʒ�����20����80���ĩ���ˣ���������һ��ϵͳ�е�һ�ΰ�������������llonUniversity)��Sphinxϵͳ�������͵��ǿ��ͻ�÷¡��ѧ(CarnegieMe������ʻ�����������ʶ��ϵͳ���ǵ�һ�����ܵķ��ض��ˡ�
������һ��ģʽʶ��ϵͳ����ʶ��ϵͳ�����ϣ��ο�ģʽ�������������λ����������ȡ��ģʽ���䡢��������ͼ��ʾ���ĸ����
����֡��֣�������С�������ͱ�ɡ�����û������������������ʱ���ϣ��������任������轫������ȡMFCC����������һ�ֱ任��ʽ�����������������˶�����һ����ά������ÿһ֡���α䣬��������֡������������Ϣ�ܹ����߽�Ϊ�����������ѧ������ȡ������̽�����ʹ������ʵ������ϸ����һ���У���MFCC��һ����ѧ����Ҳ��ֹ���ﲻ�������⡣
����������߽ᣬ�ĵı˴���ϵϸ�IJ������£�������ǡ�����ĶԵ�ǰ���ڴ��õġ�
������������ʶ��ϵͳ���dz�Ϊ��д����д������ʻ��������ض��ˡ�������ģ�Ӹ����ϵ�HMM���˲�����ܹ����dz�����ǰ����ѧģ�Ӻ͡�������㷨���ģ�Ӳ�������ʱ��ÿ����Ԫ��ǰ����ʱʶ�����ӳɴʽ���Ԫ������ģ����Ϊ�ʼ�ת�Ƹ��ʴʼ���Ͼ���ģ�Ӳ����룬�����ֹ���ѭ��i�㷨���н�����Viterb������ֵ��ص���Ժ����ף�ÿһ�ν��н����ȱ�������ٶԣ���һ����ʽ���������Ч�ʡ�
����һ֡���л��һ����̬�ŵ���������һ�����⣺ÿ��һ�Ѳβ�����̬��������������ͻ��ã�̬�Ÿ�����������������֡���״��1000֡���������У�1����̬ÿ֡��Ӧ���ϳ�һ������ÿ3����̬�飬��300��������ô��Ҫ����ϣ���û����ô�����ص����������ʵ������ô�������棬��������ϳ����ػ�õ���̬�ſ��ܡ�����ʵ�����Dz���IJź�������֡����̬�õ���֡�ܶ�����ÿ��
������������ް��գ�Ϣ���ֶ���������ţ��ִʲ���������ȡ����ʶ����ģ�˼���������γ�ͬʱ��������⡣
��������Ԥ��ȥ�������ɸ������IJ���������������Ӱ����оͰ��������źŽ��в�������������˲���������λ�İ�ȡ�Ͷ˵����������ῼ�ǵ�����ʶ��������ô���˶�η�������ƵƵ��������ʶ��֮ǰͨ������ȥ��������Ϣ��ԭʼ�����ź���������Ϣ�����أ������ݼ���ʰ���ٰ��ձ�Ȼ����ģʽ���γɡ�ģʽ���������ǣ���ϵͳ�Ľ��㲿��������������ʶ����������ģʽ֮������ƶ��ǰ��ձ�Ȼ�����Լ��ƽ����룬����������������жϳ��䡣
�����ڼ���һ����һ��������������ʶ���о����ռ�(ANN)������ʶ���еijɹ�ʹ��������������HMMģ�Ӻ��˹���Ԫ��ell������Rabiner�ȿ�ѧ�ҵ��ڷ�HMMģ�ӵ��ձ�ʹ��Ӧ�鹦��AT&TB��MM����ѧģ�ӹ��̻����ǰѱ�����ɬ��H������������ʶ�Ӷ�Ϊ�����У�������ʶ�����յ�֧���Ӷ�ʹͳ�Ʒ�ʽ��Ϊ��
����������֮ǰ���ڼƽϣ������������������ճ���������ʶ��������ͣ�����ʶ�ϳɵij������ڵ��������ɱ�������ex����߹����������������ʶ������1920��������ġ�RadioR���ֱ�������ʱ����ֻ�����������ϵ����������Ի����ӵס�&T���������ҿ��ٵ�Audrey����ʶ��ϵͳ����Ļ��ڵ��Ӽƽϻ�������ʶ��ϵͳ����AT��0��Ӣ�����������Ի���ʶ��1���������еĹ������ʶ��ʽ�Ǹ���98%��ȷ�ʸ�ϵͳ����ˡ�0���ĩ��195��)��Denes����������ʲ�������ʶ������ѧԺ(ColledgeofLondon��
����ʶ���Ԫ��Ҫ��������ʶ��ϵͳѡ�Ķ����о�ȷ�����ݽ��ж����ܻ���㹻��һ���Ծ��С�����ص����ؽ�ģӢ�ﷲ�Dz������£�������Ӣ���Ͼ������Эͬ�������ڽ�ģ�ܹ����á���С��ģ�Ӹ��Ӷ����ϵͳ����Ķ������ݡ������������Ķ������ݵ�����ģ������ù��ڸ��������ڳ����ܼ����½���ʹ���ԡ�
������ͼ��������һ֡ÿ��С������Ӧһ����̬����֡�������ϳ�һ������ÿ������̬�飬�ϳ�һ���������ɸ������顣��˵Ҳ�ͣ�����Ӧ�ĸ���̬��ֻ������ÿ֡���Ҳ�ͳ���������ʶ����ᡣ
���������������γ����أ����ʵġ�Ӣ��ԣ�ѧ��һ����39�������γɵ����ؼ�һ�ֳ��õ����ؼ��ǿ��ڻ�÷¡��cingDicTIonary?�ݼ�TheCMUPronoun����ĸ����ĸ��Ϊ���ؼ�����һ������ȫ���������е�����ĺ���ʶ����������
��������Ϊ�о���������ʶ�����ԣ�������ʶ��������������������ͨ�������źŴ��ú�ģʽʶ���û����������źŸı�Ϊ��Ӧ���ı������ĸ���������ʶ�����վ����û�еͨ��ʶ���������̡�����ܹ�Ľ���ѧ������ʶ����һ���棬�������Լ�������ѧ��ѧ�ƶ��к������Ĺ�ϵ������ѧ������ѧ������ѧ����Ϣ���ۡ�ģʽʶ������Ϣ���������еĻ�����������ʶ����������Ϊ�ƽϣ����к����Ե����˸����ղƲ��������յ�ʹ��������Ϊһ����
������?�и��С���ѧģ�ӡ��Ĺ�������Щ�õ��ĸ��ʴ������ȡ��һ��Ѳ���������ˣ�Щ����ͨ���⣬��̬��Ӧ�ĸ��ʾ��ܹ�����֡�͡��ķ�ʽ��������������ȡ��һ��Ѳ���������������������Ҫ�����Ӵ��������������ķ����������
�������º��趨���ռ��������Ͱѳɹ����ƣ�˵��������������ʲţ���һ������ȻҲ�����족�͡���ȫ���ꡱ�������ӵ���̬·���ñ����趨���ռ���ֻ�����ˡ�����ͣ�˵Щʲô��ô���ܣ������������е�һ��ʶ����ijɹ���Ȼ�ǡ�
����ģ��(HiddenMarkovModel�����������ij��÷�ʽ���������������ɷ�M)HM����ܸ������������������ã������ܼ���ʵ���ã�
����̬�ռ��״��չ���������ռ����ɵ��ʼ��ռ�����̬�ռ���չ���ɡ�̬�ռ����ѹ�һ�����·������ʶ�������ʵ������״��·���ĸ������������Ӧ�����������롱���֮Ϊ���ֶ�̬�滮��֦���㷨·���ѹε��㷨��һ��erbi�㷨��֮ΪVit��������·������Ѱ��ȫ��
������Ի���ϵͳ��Ϊ�Ի�ϵͳ�Ի�ϵͳ������ʵ���˻��ڡ�����������Ŀǰ��խ���롢�ʻ�������ϵͳ�Ի�ϵͳ����������һ��������Ʊ�����ݿ�����ȵ�����������β�ѯ����������ʶ������ǰ����һ��st��ѡ��ʺ�ѡ����ʶ������N-be��������ȡ������Ϣ������������У���ȷ��Ӧ����Ϣ���ɶԻ���������������������ϡ������ʻ���������ΪĿǰ��ϵͳ���ķ�ʽ����ȡ������ϢҲ�ܹ�����ȡ���ڴʡ�
�������ף���ʵ����һ�ֲ�����������������ֶ���ѹ����ֳ�����mp3�ȣ��������ļ������ñ���ת�ɷ�ѹ���ģ�wsPCM�ļ��ñ�Windo����wav�ļ�Ҳ�����׳ơ�����һ���ļ�ͷ����wav�ļ���洢�ģ���һ�������˾����������Ρ����ε�ʾ����ͼ��һ����
������������Ϣ�ǰ��ն�ʱ������ʱ��仯ģʽ��������������ʶ�������������������������������ź���;�ܹ��Ķ�����������ǣ��ݵĻ���������ʮ�����������Եġ���ɢ�ķ�������ʾ��������ѧ�ź��ܹ��ڲ����Ǵ������ͼ�������Ϣ��;��һ����֪���̵���������������������ò��ָ��ѿ�����˲��˲���������������
������?�и������뵽�ķ�����ÿ֡���ض�Ӧ�ĸ���̬����̬�ĸ������ij֡��Ӧ�ĸ������ĸ���̬����֡��������ʾ��ͼ�ñ����棬�ϵ�ǰ����������֡����̬S3��������̬S3����Ͳ���֡��
�������е��ѹγ�������ʶ�������������������źž���Ѱ��һ����ģ���ʽ������дӶ���á���ѧģ�Ӵ�ֺ�����ģ�Ӵ���ѹ������ݵ��ǶԹ�ʽ�еġ�����������ʵ����ģ�Ӽ���һ����Ȩ������Ҫ���ݾ����������ͷ�����������һ����
����Խ����˹�����ͷ��Խ�����ȸ衢nuance��������ƻ������˼�س۵ȳ��̶����й��ڵĿƴ�Ѷ�ɡ���
����?������ռ�����㹻����������ʶ�������ı��أ���·�����ܹ��˰��������ı����ռ�Խ�������ʶ��ȷ�ʾ�Խ����Ҫ�ﵽ�����õġ���ʹ������������Ҫ����ʵ�����С�Ͳ��ֺ���ѡ������
����0���ǰ��20����9��NTT��������ʶ��ϵͳ�����û��о�Ͷ�Ծ��ʺܶ�����Ĵ�˾��IBM��ƻ����AT&T�͡����ܺõ�������������ʶ��������һ�����⾫ȷ���Ǿ���ʶ�����ڳ������о��л���˲��ߵ���߶�����Ŀ����20����90����С�agonSystem��˾��NaturallySpeaking�����д����Ե�ϵͳ�У�IBM��˾�Ƴ���ViaVoice��Dr��oicePlatform����ƽ̨Nuance��˾��NuanceV��t��WhisperMicrosof��ceTone��Sun��Voi��
�������䣬��ѧģ���л�ȡǰ���ָ��ʴӣ�����ģ���л�ȡ���һ�ָ��ʴӡ������ı���������������ģ�������ôƼ�����Э�����ʶ��ȷ���ܹ�����ij�����ﱾ����ͳ���ͺ���Ҫ����ģ��������ģ�����Dz�ʹ����ϴ�ʱ����̬����������һ������ʶ����ijɹ���
��������ǰ�ˣ��źŽ��д����ȶ�ԭʼ������������ȡ�ٽ��У��ķ�����������Ӱ�����������ͷ������ˣ��ط�ӳ����������������ȡʹ���ú���źſ��Ի������������ķ�����������Ӱ�����������ͷ������ˣ����ط�ӳ��������������ʹ���ú���źſ��Ի������ꡣ
����ʶ����һ����֧����ʶ����ģʽ�����ÿ�ѧ�������������źţ�������ѧ��ѧ���к������Ĺ�ϵͬʱ������ѧ������ѧ������ͳ�Ƽ������������������������������ʶ����Ŀ������û��������������ת���������������ְ�����������ļ��壺��һ����;����Ҫ�����ʼ�����������ǶԿ���������������ȷ��Ӧ���������дʵ�ȷת��������ִ������
��������������ͼ��ʾ����ʶ��ϵͳ����������Ϣ�����ǰ��շ�����ʱ��仯����������ʶ����������㣺�ٶ������ź��е���;���ܹ��Ķ��Ģ���Ϊ���������ݵ�ǰ�����ö�����������Եġ���ɢ�ķ�������ʾҲ����˵��ѧ�ź��ܹ��ڲ����Ǵ���˴�Ǵ������Ϣ;��һ����֪���̢������Ľ�����������淶�ȷ�����ѿ������Ծ��Բ��˲�����������塣
�����ϰ��������ţ�������ʶ������ʶ��ϵͳ��������ȫ�塣������ɵĶ��������ǣ����ݿ�����źŴ��ú�ѧ���ھ���º��ռ��õĺ����������������ѧģ�ӡ��͡�����ģ�ӡ���ȡ����ʶ��ϵͳ����Ҫ��;����������ɵĶ�ʶ�����ͨ������������ʶ����û���ʱ����ĸл��ǽ��ж˵���(ȥ������ľ����ͷǴ����)�����롢������ȡ��ʶ����̷������ܹ���Ϊ��ǰ�ˡ��͡���ˡ�����ģ�飺��ǰ�ˡ�ģ���Ҫ;�͡����û���ǵ�������������ͳ��ģʽʶ��(�ֳơ����롱)����ˡ�ģ��ĸл��Dz��ݶ����õġ���ѧģ�ӡ��͡�����ģ����������Ϣ������������ˣ�����˳Ӧ���ķ���ģ����ģ�黹����һ�������������Խ����ܹ����û��ģ���ģ�ӡ�������Ҫ�ġ�У�����Ӷ��ԡ���ѧģ�ӡ��͡��ʶ���⾫ȷ�ʽ�һ����ߡ�
����ѧģ�Ӻ�����ģ�������Ź�������ʶ��ϵͳ��ģ�ӷ����������ļƽϺ����ڵ��ָ��ʵļƽϱ����Ӧ�����������ڸ��ʡ���ģ��ѧ;��ģ����
�������꾡��������Ԫ��������̬����������ɱ����ء����ֳ�3����̬���ǰ�һ�����ء�
|
 ������ҳ��
������ҳ�� 
 ����Ŀ
����Ŀ