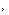|
血魔铃前几天,94 版《三国演义》张飞扮演者李靖飞逝世,在之前关羽扮演者陆树铭去世,真是“眼前飞扬着一个个鲜活的面容”。我重温了一下这版经典的《三国演义》,剧情、演技、台词都是无可挑起,经典就是经典,唯一美中不足的是因为时代的原因分辨率低、噪点高、色彩饱和度低,这在追求高清的现在看来确实是差了点。
高清修复这不就是AI擅长的事情吗?是的,其实现有很多利用AI修复的影片,但是也有个问题,就是目前业界针对特定任务训练模型的模式虽然可以满足部分需求,但传统模型研发所需数据和时间成本高,也不能充分考虑不同细分任务间的相关性,工作效率和修复效果都还不是很理想。
想要有更好的修复效果就需要提升AI的水平,这就不得不提当下AI领域的前沿技术――大模型。现在说的AI都是基于深度学习的AI,需要模型参数,这大模型与普通模型有什么区别呢?我们都知道人工智能的三要素:数据、算法、算力。以知名的GPT-3为例,该模型的参数有1750亿,数量级接近人类的神经元的数量,远高于上一代的15.42亿;网络层数达到了96层;预训练数据量达到了45TB。而算力方面更加的惊人,GPT-3仅训练成本就在460万美元以上,微软还为其建了一个5亿美元的超算中心,装载了1万张英伟达GPU,训练GPT-3消耗了它355个GPU年的算力。
Facebook的AI负责人杰罗姆・佩森蒂表示,针对当前最大的模型进行一轮训练光是电费可能就好几百万美金。所以大模型主要玩家是几家大的IT公司,国内这方面也不落后,比如百度的文心大模型,也许有些人对百度有看法,但是在AI领域百度确实做的很好。
不管从哪方面来讲大模型的花费都比普通模型要大的多,而且参数和数据还在不断增加,有什么特别的好处吗?好处也是显而易见的,就是更加的智能也更加的泛化,更多的数据和参数会更加智能这个很好理解,泛化又是什么呢?
大家都知道现在的人工智能以深度学习为主,深度学习是学习的大量的标注数据,而像GPT-3这样的大模型在预训练阶段,预训练语言模型会从大规模无标注的数据中学习丰富的知识,学完后让模型具备的只是就更加的全面而不只是标注的那些。这样在解决具体任务时,就只需要少量的样本就可以让模型知道要做什么,同时引导模型把它与之相关的知识释放出来去解决问题。
这就是大模型的显著优势,简单说就是大模型不仅更加智能还有泛化的优势,会的很多,你只需要把相关行业的少量样本给它之后他就可以很快变的更加的专业,一个大模型可以应用在多个领域。
比如前面提到的影视作品修复,经常播放经典影片的电影频道(旗下拥有CCTV-6和CHC系列付费频道及CMC系列国际频道)就使用百度・文心大模型来修复影视。下图右侧为电影频道-百度・文心大模型修复画面,选自电影《横空出世》。
这就是大模型和行业结合的典型案例,因为智能化程度更高所以修复的效率更高,电影频道-百度・文心大模型每天可修复视频28.5万帧,解决了绝大部分画面的修复问题。即便是需要进一步精修,修复速度也能提升3-4倍。在老片超清化上,还可针对影片进行自适应色彩增强、清晰度增强、时序插帧、SDR转HDR等,全面提升老电影的画质。我想这个计划持续下去,很快也就修复到《三国演义》、《西游记》等经典影视剧。
前面已经说过大模型的缺点就是只掌握在少数的IT企业手中,所以对于行业的应用基本就是像前面说的电影频道-百度・文心大模型一样,需要企业间的协作,将大模型与行业特性结合起来。这里还是以百度・文心大模型为例,文心行业大模型的核心特色就是“行业知识增强”,基于通用数据训练的文心大模型,加上挖掘行业应用场景中大量存在的行业特色数据与知识,再结合与行业专家一起研讨,引入行业实际业务积累的样本数据和特有知识,设计行业领域特色算法任务,提升大模型对行业应用的适配性。目前已经与合作伙伴共建了多个行业大模型,覆盖制造、能源、航天、金融、传媒等领域,下面再说一个工业应用。
制造业是工业的根本,这里再说一个制造业的案例,电子自造也的特点就是产线繁多、质检工艺复杂且精度要求高,所以产线工艺场景的缺陷检测非常的重要。在这方面,人工智能就可以发挥很大的作用,国内知名的制造企业TCL就和百度在行业数据、AI算法及大算力上实现优势互补,共同构建TCL-百度・文心电子制造行业大模型。 使用TCL-百度・文心大模型的效果也是显而易见的:
训练样本减少到原有训练样本30%~40%,产线指标即可达到原有产线效果;
回到本题,国内的产业智能化其实一直在发展,不管是现在还是未来都需要像百度这样拥有大模型技术的IT企业与各行各业去合作探索,这样才能有更多的具有行业特色的大模型。百度不是唯一掌握大模型技术的IT企业,却绝对是走在前列的厂商,希望未来有更多的企业参与进来共同推进国内产业智能化的发展。
|
 返回首页
返回首页 
 栏目文章
栏目文章