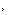|
|
|
| NVIDIA发布新的人工智能模型可以根据文本描述生成3D模型 |
|
| 作者:佚名 文章来源:本站原创 点击数: 更新时间:2022/11/24 13:07:03 | 【字体:小 大】 |
|
84aaa改成什么了近日,英伟达(NVIDIA)的研究人员发布了 Magic3D,这是一种人工智能模型,可以根据文本描述生成3D模型。在输入诸如“一只蓝色毒镖青蛙坐在睡莲上”这样的提示后,Magic3D 在大约40分钟内生成了一个带有彩色纹理的3D网格模型。经过修改,得到的模型可以用于视频游戏或CGI艺术场景。
在其学术论文中,NVIDIA将 Magic3D 定义为对 DreamFusion 的回应,DreamFusion是谷歌研究人员在9月份宣布的一种文本到3D的模型。与 DreamFusion 使用文本到图像模型来生成2D图像,然后将其优化为体积 NERF(神经辐射场)数据的方式类似,Magic3D使用了一个两阶段过程,该过程采用以低分辨率生成的粗略模型,并将其优化到较高分辨率。根据论文作者的说法,Magic3D方法生成3D对象的速度比 DreamFusion 快两倍。
Magic3D还可以对3D网格进行基于提示的编辑。比如,给定一个低分辨率的3D模型和一个基本提示符,可以通过修改文本来更改结果模型。此外,Magic3D的作者还演示了在几代作品中保持相同的主题(通常称为一致性的概念),并将2D图像的风格(如立体派绘画)应用到3D模型。
从文本生成3D的能力,感觉就像是当今扩散模型的自然进化,在对大量数据进行密集训练后,这些模型使用神经网络来合成新内容。仅在2022年,我们就看到了强大的文本到图像模型的出现,如Dall-E和稳定扩散,以及来自Google和Meta的基本文本到视频生成器。谷歌在两个月前也推出了前面提到的文本到3D模型 DreamFusion,从那时起,人们就采用了类似的技术来作为基于稳定扩散的开源模型。
至于Magic3D,研究人员希望它能让任何人在不需要特殊训练的情况下创建3D模型。一旦得到改进,由此产生的技术可能会加快视频游戏(和VR)的开发,或许最终会在电影和电视的特效中找到应用。在论文的最后,他们写道:“我们希望通过Magic3D,让3D合成大众化,让每个人都能在3D内容创作上发挥创造力。”
|
|
 栏目文章
|
|
|
|
 返回首页
返回首页